Paper Review
[Paper Review] Multi-Concept Customization of Text-to-Image Diffusion (Custom Diffusion)
seunkorea
2023. 12. 11. 14:32
CVPR 2023. [ArXiv] [Website] [Github]
Adobe Research
Multi-concept Customization of Text-to-Image Diffusion
Multi-concept Customization of Text-to-Image Diffusion, 2022.
www.cs.cmu.edu
이번 글에서는 Adobe Research에서 발표한 Custom Diffusion 논문리뷰를 진행하겠습니다.
Key Point
1. text-to-image diffusion model의 cross-att. layer의 일부만 fine-tuning하는 새로운 방법 CustomDiffusion 제안
2. 모델의 전체 파라미터를 fine-tuning 하지 않으므로 fast & efficient
3. multiple concept generation을 위해서 jointly train, closed-form constrained optimization 방법론 제안
Introduction
- text-to-image generation 모델들의 발전으로 매우 다양한 객체와 스타일, 장면의 이미지들을 생성할 수 있게 되었습니다.
- 일반적이고 다양한 generation 능력을 확보
- 하지만 여전히 대부분의 사람들이 자신의 개인적인 경험을 모델에 종합하기를 원합니다.
- 예를들면 "일반적인" 강아지가 에펠탑 앞에 서있는 사진이 아닌 "자신의 강아지"가 에펠탑 앞에 서있는 사진과 같은 경험을 원하는 것입니다.
- 그래서 text-to-image model의 customization 개념 대두되었는데요.
- 기존의 text-to-image diffusion 모델을 파인튜닝해서 concept customization을 가능하게 하게하려면 fine-tuning 모델은 기존개념을 일반화하고 합성해서 새로운 변형을 생성할 수 있어야 합니다.
- 하지만 모델은 이 과정에서 기존의 개념을 잊거나 변형시켜버리는 경향이 있습니다.
- 예를 들면 아래의 그림처럼 "moongate"라는 새로운 개념을 학습하고자 할 때 "moon"과 "gate"의 의미를 모두 잃어버리는 현상을 확인할 수 있습니다.

- 또한 몇 장의 이미지만으로 모델을 fine-tuning하는 경우에 이 몇 장의 이미지 샘플에 오버피팅 되는 경향이 있습니다.
- 추가로 논문의 저자들은 single concept에 대한 튜닝 뿐만아니라 multi-concept 튜닝에 대해서도 연구를 진행했는데 multiple concept 확장과정에서 각 개념들이 혼합되는 문제가 발생했다고 합니다.
- 따라서 본 논문에서는 위에서 언급한 문제들을 해결할 수 있는 text-to-image diffusion model을 위한 fine-tuning 기법인 Custom Diffusion을 제안합니다.
- 해당 방법에서는 모델의 전체 파라미터를 full fine-tuning하지 않고 모델의 cross-att. layer의 일부분만 tuning 하는 방식을 사용합니다.
- 이 부분만 fine-tuning하는 것만으로도 새로운 개념을 모델에 학습시키기에 충분하다는 것을 발견했다고 합니다.
- 그리고 전체 파라미터를 업데이트 하지 않기 때문에 계산과 메모리 측면에서 효율적입니다.
- 모델의 망각을 방지하기 위해서는 우리가 생성하고자 하는 타겟 이미지와 유사한 캡션이 있는 이미지 세트를 학습에 추가로 사용했습니다.
- 이렇게 데이터셋을 augmentation 방법을 도입해서 학습의 수렴속도를 높이고 결과를 개선했습니다.
- multiple concept을 학습시키기 위해서는 jointly train 방식과 closed-form constrained optimization 방식 을 사용했습니다.
- 자세한 방법론과 이론적인 내용은 아래에서 살펴보도록 하겠습니다.
- Custom Diffusion 방식을 사용해서 Stable Diffusion 기반의 모델을 backbone으로 사용해서 최소 4개의 이미지로 fine-tuning했을 때
- single concept에서는 현재 진행되고 있는 연구들보다 더 나은 text-alignment 성능을 보이고 target image와 visual similarity가 더 높았다고 합니다.
- 또한 multiple new concept을 구성할 수 있었고 계산과 메모리 측면에서 효율적인 결과를 얻었다고 합니다.
Method
- 위에서 미리 한 번 언급했지만 본 논문에서 제시하는 fine-tuning 전략은 다음과 같습니다.
- 모델의 cross-att layer의 일부 가중치만 업데이트한다.
- 몇 개의 훈련샘플 이미지에 과적합되는것을 방지하기 위해서 실제 이미지의 정규화세트를 사용한다.
- 각 방식에 대해서 조금 더 자세하게 알아보겠습니다.
Single-Concept Fine-Tuning
- 일반적으로 다루어졌던 Single-Concept Fine-Tuning task의 목표는
- 사전학습된 text-to-image diffusion model에 4개의 이미지와 그에 해당하는 텍스트 description을 통해서 모델에게 해당 single concept을 학습(임베딩)시키는 것이라고 할 수 있습니다.
- 이렇게해서 미세조정된 모델은 텍스트 프롬프트를 기반으로 사전학습 과정에서 학습한 prior knowledge를 유지한채로 single concept generation이 가능하게 해야합니다.
- 본 논문에서는 backbone 모델로 LDM (Latent Diffusion Model) 계열의 Stable Diffusion을 사용했습니다.
- Diffusion 모델은 고정 길이(일반적으로 1,000) MC의 reverse process를 학습합니다.
- 즉, Timestep $t$에서 noisy한 이미지 $x_t$가 주어지면 모델은 이전 시점의 $s_{t-1}$을 얻기 위해서 입력이미지의 Noise를 제거하는 방법을 학습하는 것이 Diffusion 모델의 학습 프로세스 입니다.
- 이 과정을 수식으로 단순화해서 나타내면

- 본 논문에서 backbone 모델을 Diffusion 모델을 사용했기 떄문에 이전에 언급했던 목표로 텍스트-이미지 쌍에 대해서 loss를 업데이트 하는 과정을 거칩니다.
- 하지만 loss를 최소화하기 위해 모든 레이어를 업데이트 하면 대규모 모델의 경우 계산이 비효율적이고 몇 개의 이미지에 대해서 fine-tuning 시켰을 때 오버피팅에 노출되기 쉽다는 문제점이 있습니다.
- 따라서 본 논문의 저자들을 fine-tuning 과정에서 업데이트 되어야 하는 최소한의 가중치를 식별하는 것을 목표로 삼았습니다.
Rate of change of weights
- 그래서 저자들은 loss를 사용해서 타겟 데이터셋(e.g. "나의" 강아지, 논문에서는 moongate 개념)에서 fine-tuning될 때 세 가지 레이어의 파라미터 변화를 분석하였습니다.
- Cross-att. -> 텍스트와 이미지 사이
- Self-att. -> 이미지 자체
- 나머지 (conv., norm.)
- 파라미터의 변화는 다음과 같은 식으로 계산하였으며 세 가지 레이어의 파라미터 변화율을 비교한 결과는 다음과 같습니다.

- 위의 그림에서 확인할 수 있다시피 Cross-att. 레이어의 파라미터가 나머지 파라미터들에 비해 상대적으로 높은 변화량을 갖는 것을 볼 수 있습니다.
- 이는 곧 Cross-att. 레이어가 모델의 전체 파라미터에서 단지 5% 비율만 차지함에도 fine-tuning 과정에서 업데이트 되는 주요 파라미터이며 중요한 역할을 한다고 해석할 수 있습니다.
Model fine-tuning
- 지금까지 우리는 모델의 fine-tuning 과정에서 cross-att. 파라미터들이 중요한 역할을 한다는 것까지 발견했습니다.
- 모델에서 cross-att. 블록은 조건 feature에서 모델의 Latent feature를 수정하는 역할을 합니다.
- text-to-image task에 적용하면 diffusion model에서 cross-att. 블록은 텍스트 feature를 조건으로 해서 latent image feature를 수정하는 역할을 한다고 할 수 있습니다.
- attention 연산을 우리의 상황에 맞게 살펴보면 주어진 텍스트 feature $c \in \R^{s \times d}$와 latent 이미지 feature $f \in \R^{(h \times w)\times l}$에 대하여 single-head cross-att. 연산은 다음과 같습니다.

- 그리고 attention 블록의 출력값으로 latent image feature가 업데이트 되는 것입니다.
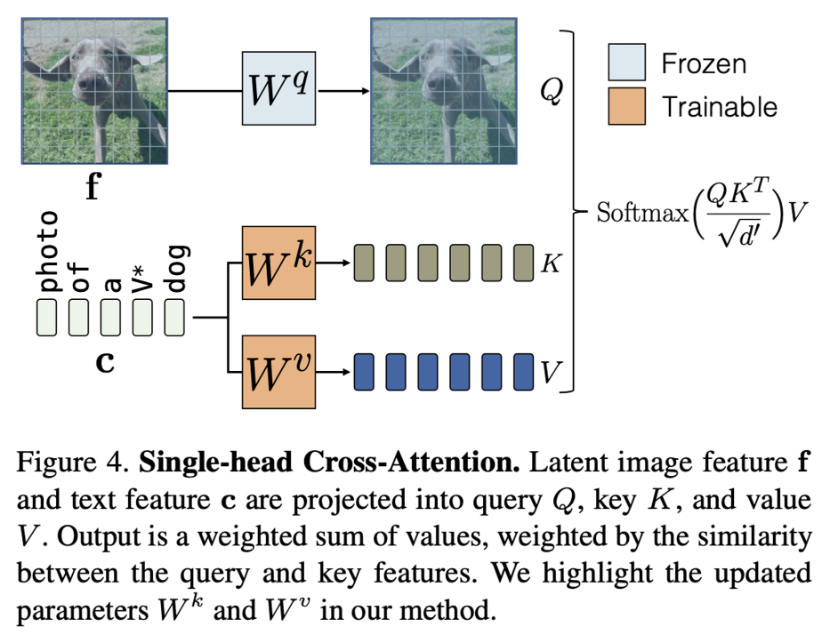
- 위 그림으로 다시 한 번 살펴보자면
- 우리의 task에서 모델을 fine-tuning 한다는 것은 주어진 텍스트에서 이미지 분포로의 매핑을 업데이트 하는 것이고
- 텍스트 feature는 $W^k$, $W^v$에만 입력되기 때문에 fine-tuning 과정에서 업데이트 해야하는 파라미터는 $W^k$, $W^v$로만 설정해도 된다는 것을 알 수 있습니다.
Text encoding
- 우리가 모델에 Input으로 넣어주어야 하는 것은 새롭게 생성하고자 하는 target concept의 이미지 뿐만 아니라 이에 대한 텍스트 캡션도 필요합니다.
- target 이미지에 이미 텍스트 설명이 있는 경우 이를 텍스트 캡션으로 사용하였고
- target concept이 일반 카테고리의 고유한 인스턴스라면(즉, 개인적인 사례 e.g. petdog) target concept을 나타내는 클래스 앞에 rare-token $V^*$을 추가하여 입베딩하였습니다. (e.g. $V^*$ dog)
- 그리고 여기서 $V^*$토큰은 rare-token 임베딩으로 초기화되고 cross-att. 파라미터와 함께 최적화됩니다.\
Regularization dataset
- 지금까지 우리가 single concept fine-tuning을 위해서 cross-att. 레이어에서 텍스트의 latent feature로의 key, value 매핑만 식별해서 해당 부분만 fine-tuning 하기로 했습니다.
- 하지만 이렇게 하더라도 실제 target concept과 이에 대한 텍스트 캡션 쌍을 이용해서 fine-tuning을 진행했을 때 language drift 문제가 발생했다고 합니다.

- 이러한 현상을 방지하기 위해서 본 논문의 저자들은 LAION-400M 데이터셋에서 target 텍스트 프롬프트와 높은 유사도를 가진 캡션을 가진 200개의 정규화된 이미지를 선택해서 추가적인 데이터셋으로 활용하는 방식을 도입했습니다.
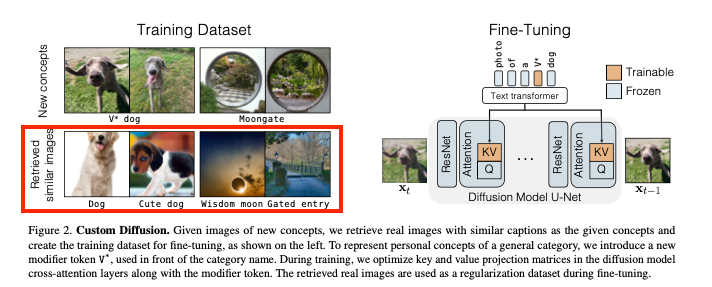
- 위의 그림에서처럼 내가 모델에게 주입시키고 싶은 new concept과 유사도가 높은 이미지를 추가적인 학습데이터셋으로 활용한 것입니다.
- 이렇게 해서 User의 이미지 몇 장만을 가지고 새로운 개념이나 개인적인 개념을 모델에게 학습시키고 single-concept generation을 가능하게 만들었습니다.
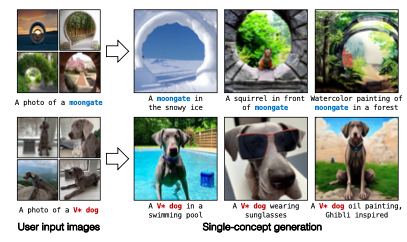
Multiple-Concept Compositional Fine-tuning
- 본 논문에서는 single-concept을 모델에게 임베딩 시키는 것 뿐만아니라 multiple-concept을 모델에게 학습시키고 multiple-concept이 서로 섞이지 않고 잘 구성되도록 하기 위한 방법을 연구했습니다.
- 지금까지는 "moongate" 개념, "나의 강아지" 개념을 개별적으로 모델에게 학습시켰다고 한다면 이제는 "나의 강아지"와 "moongate" 개념을 (multiple-concept)을 모델에 주입해서 "나의 강아지"가 "moongate" 앞에있는 사진을 생성하도록 하는 것입니다.
- 그리고 이 때 주입하는 두 개의 개념이 서로 섞이거나 하지 않도록 주의가 필요합니다.
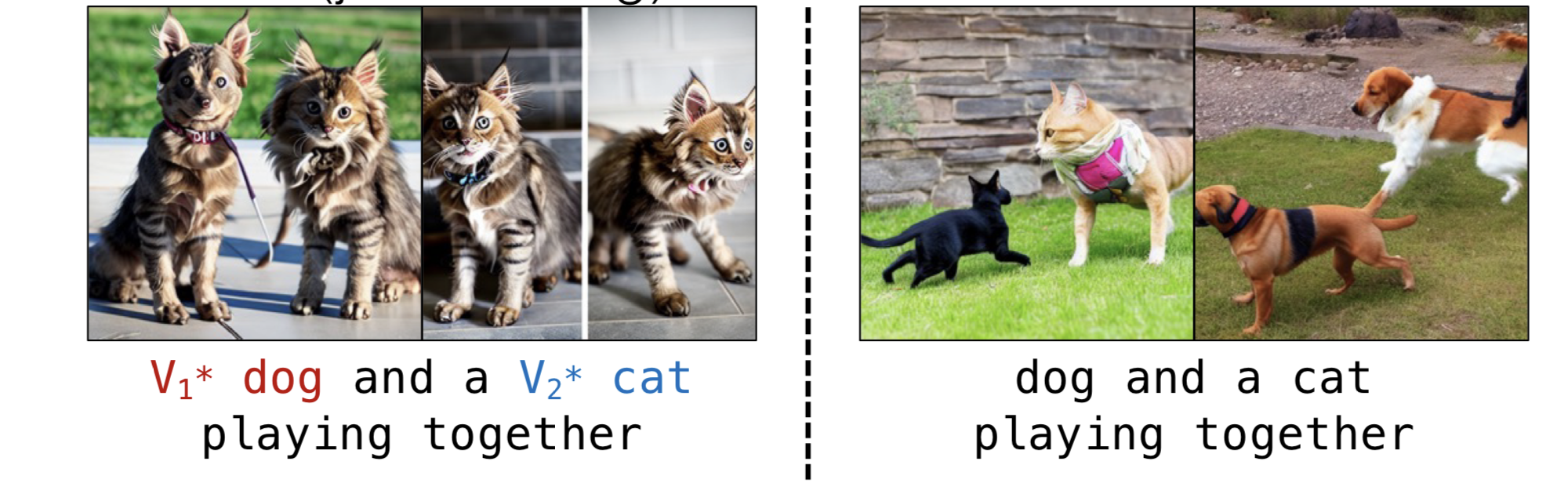
- 아래의 그림처럼 dog와 cat의 개념을, 그리고 tortoise plushy와 Teddybear를 동시에 두 개념을 함께 주입했을 때, 두 개념이 섞인 것을 확인할 수 있습니다.

1. Joint training on multiple concepts
- 이러한 현상을 막기 위해 Multiple-Concept Compositional Fine-tuning을 위한 첫번쨰 방법은 Jointly train하는 방법입니다.
- 각각의 개별 개념을 위한 학습 데이터셋을 합쳐서 single concept method에서 사용한 방법으로 학습을 진행합니다.
- target concept을 나타내기 위해서 서로 다른 rare-token으로 초기화된 서로 다른 modifier 토큰 $V_i^*$를 사용하고 각 레이어에 대한 cross-att.의 K, V projection 행렬과 함께 최적화하는 방식입니다.

2. Constrained optimization to merge concepts
- 논문에서는 multiple concept을 위해서 다른 방법도 사용했는데요.
- 두번째 방법은 constrained optimization 방법입니다.
- 이 방법은 위에서 보았듯이 Fine-tuning 과정에서 텍스트 feature에 해당하는 key, value projection 행렬만 업데이트하였습니다.
- 따라서 연속적으로 여러 single concept 모델들을 constrained optimization을 하나로 merge해서 multiple concept 생성을 가능하게 하는 전략입니다.
- 과정은 다음과 같습니다.

- 직관적으로 위의 식을 살펴보면 원래 모델의 행렬을 업데이트 해서 $C$의 타겟 캡션에 있는 단어가 fine-tuning된 개념 행렬에서 얻은 값과 일관되도록 매핑하는 것을 목표로 하는 것을 확인할 수 있습니다.
- 결국 위의 목적함수는 $C_{\rm{reg}}$가 퇴화하지 않고 솔루션이 존재한다고 가정할 때 Language multipliers를 사용하여 다음과 같이 closed-form으로 풀 수 있게 됩니다.
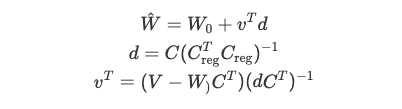
- 1에서 본 Joint 학습 방식에 비해서 이 방법은 각 concept별로 Fine-tuning 모델이 있는 경우에 더 빠르다고 합니다.
- 이렇게 저자들은 두 가지 방법을 제안하였고 그 결과 단일 장면에서 두 가지의 새로운 개념을 일관되게 생성하는데 성공했다고 합니다.
Experiments
- 실험과 관련된 기본적인 정보는 다음과 같습니다.
Training details
- single-concept 250 steps train
- two-concept 500 steps(two-concept joint training)
- 배치사이즈 8
- 학습률 $8 \times 10^{-5}$
- 훈련중에 랜덤하게 target 이미지를 x$0.4 - 1.4$ resize 하였고 크기를 조정한 비율에 따라 텍스트 프롬프트에 “very small”, “far away”, “zoomed in”, “close up” 을 추가했다고 합니다.
- valid region에서만 손실 역전파 진행
Datasets
- 10개의 대상이 포함된 target 데이터셋
- 101개의 concept으로 구성된 CustomConcept101
Evaluation metrics
- Image-alignment: 생성된 이미지와 target concept의 시각적 유사성 평가
- Text-alignment of the generated images with given prompt: 주어진 프롬프트에 대해서 생성된 이미지와의 유사성 평가 (CLIP similarity 사용)
- KID: target concept에 대한 과적합 및 기존 개념에 대한 망각 정도 측정
Baselines
- DreamBooth, Textual Inversion, Custom Diffusion(w/ fine-tune all) 과 비교
Single-Concept Fine-tuning Results
Qualitative

- Single-Concept에 대해서 CustomDiffusion, DreamBooth, Textual Inversion 의 정성적 결과를 확인해보면
- 첫번째 "A watercolor painting of V* tortoisse plushy on a mountain(산 위에 있는 target 거북이의 수채화)"라는 프롬프트에 대해서 생성한 결과를 보면
- Textual Inversion은 target concept에 대한 prior knowledge를 많이 잃어버린 것을 확인할 수 있습니다.
- DreamBooth는 target concept은 잘 유지하고 수채화 풍도 맞지만 산 배경은 생성하지 못했습니다.
- 반면에 Custom Diffusion은 텍스트 프롬프트의 개념을 수채화로 잘 표현한 것을 볼 수 있습니다.
Quantitative
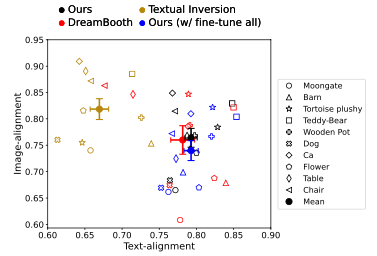
- Text-alignment, Image-alignment 결과를 살펴보면 CustomDiffusion(검은색)이 가장 우측 장단에 있는 것을 확인할 수 있습니다.
- Textual Inversion은 Image-alignment는 높지만 Text-alignment에서 많은 희생이 있는 것을 확인할 수 있습니다.
- DreamBooth와 fine-tune all 과는 이 평가 메트릭에서는 큰 차이를 보이지 않습니다.
- 하지만 같은 GPU 환경에서 학습 시간을 고려했을 때 DreamBooth는 한 시간, fine-tune all은 20분인데 비해 CustomDiffusion은 5분이 소요되었다고 합니다. 비슷한 성능이지만 학습시간에 있어서 CustomDiffusion이 효율성이 좋습니다.
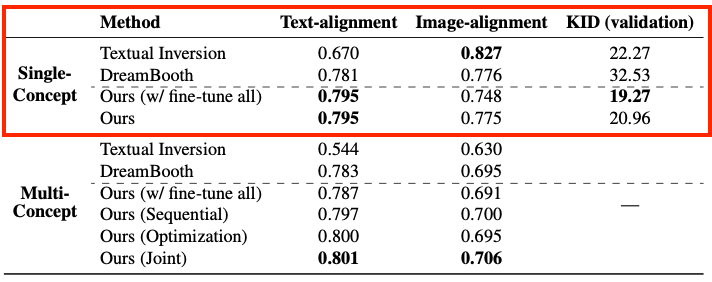
- 본 논문의 방식이 대부분의 베이스라인보다 낮은 KID를 가지고 있는 것을 확인할 수 있습니다.
Multiple-Concept FIne-tuning Results
Qualitative

- 전체적으로 Textual-Inversion의 결과가 좋지 않은 것을 확인할 수 있다. (특히 Table + Chair)
- (개인적으로) DreamBooth와는 큰 차이를 잘 못 느끼겠다.
Quantitative
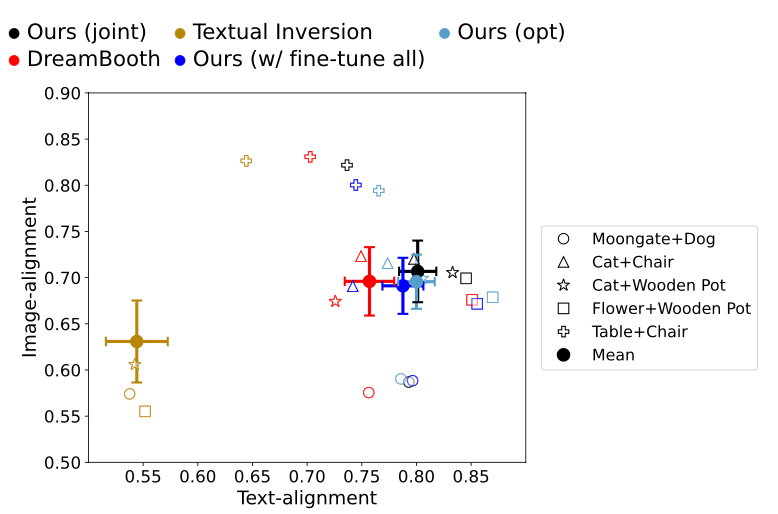
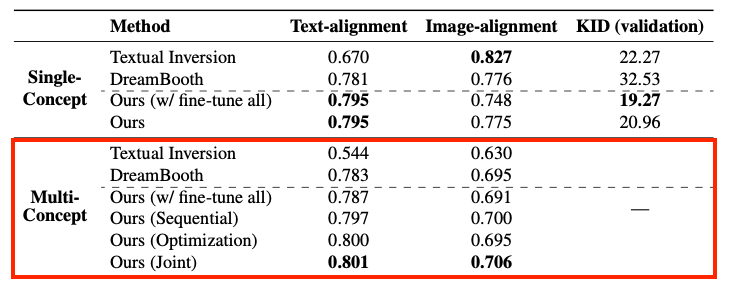
- Single-Concept 때와 마찬가지로 CustomDiffusion이 Image, Text Alignment에서 더 좋은 결과를 보이고 있습니다.
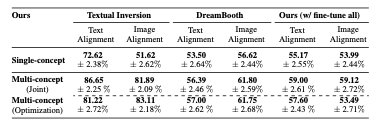
Human Preference Study
- "Which image is more consistent with the text?(어떤 이미지가 텍스트와 더 일관되게 나타납니까?)"
- "Which image better represents the objects as shown in target images?(어떤 이미지가 대상 이미지에 나타난 객체를 더 잘 나타냅니까?)"
- 라는 질문으로 사람들에게 선호도 조사를 한 결과입니다.
Ablation and Applications
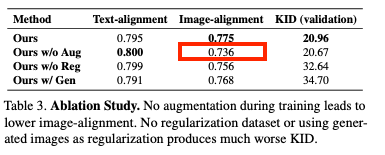
Generated images as regularization (Ours w/ Gen)
- fine-tuning 중에 유사한 범주의 실제 이미지 및 캡션을 정규화로 사용하는 대신 사전 훈련된 모델에서에서 생성된 이미지를 사용하는 방법을 비교했습니다.
- 생성된 이미지를 사용하면 대상 개념에 대한 유사한 성능을 보이지만, KID를 통해 측정되는 오버피팅의 조짐이 나타난다고 합니다.
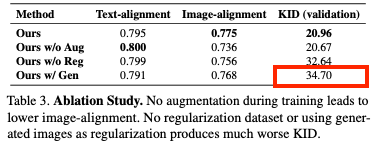
Without regularization datasets (Ours w/o Reg)
- 이 경우 모델의 이미지 alignment가 낮아지고 validation set에서 높은 KID 값을 보이는 것으로 보아 기존 개념을 잊어버리는 경향이 있다는 것을 확인했습니다.
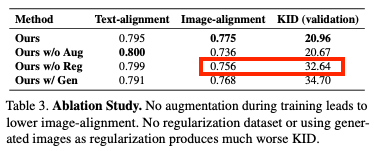
Without data augmentation (Ours w/o Aug)
- target 이미지의 시각적 유사성을 높이기 위해 진행했던 랜덤 Resize & 그에 따른 프롬프트 추가를 하지 않은 경우
- target 이미지와 시각적 유사성 감소
Fine-tuning on a style
- 특정 스타일에 대한 fine-tuning이 가능하다고 합니다.
- 텍스트 프롬프트를 "V* art의 스타일로 그린 그림" 이라고 주었을 때 해당 스타일의 이미지를 생성하는 것을 확인할 수 있습니다.

Image editing with fine-tuned models
- fine-tuning 모델을 활용해서 Prompt만으로 이미지의 일부를 수정하는 것도 가능합니다.

Discussion and Limitations
- 해당 논문에서는 몇 장의 이미지만으로 new concept, new category, personal object, artistic style에 대해서 Text-to-image diffusion model을 파인튜닝하는 방법론을 제안했습니다.
- 해당 방식은 전체 매개변수를 업데이트 하지 않기 때문에 계산 효율적이면서도
- target 이미지와 시각적으로 유사하면서 새로운 맥락에서의 변형을 생성하는 것이 가능합니다.
- 또한 multiple concept도 구성가능 하다는 점이 주목할 부분이었습니다.
- 하지만 아래의 그림과 같이 비슷한 카테고리, 비슷한 시각적 특성을 가지고 있는 Multiple object를 구성하는 단계에서는 구성 능력이 떨어진다는 점, 그리고 3개 이상의 concept에 대한 구성은 아직까지 도전적인 문제라고 합니다.
